

Large Language Models (LLMs) like GPT, Claude, and Gemini have transformed how machines interact with human language. Beyond this impressive fluency lies a deep system of mathematical modeling, data processing, and pattern recognition.
This blog walks through how LLMs work — from raw text input to final generated output — with a focus on the foundational concepts: tokenization, embedding, transformers, and prediction.
At a basic level, a Large Language Model is a type of artificial intelligence designed to understand and generate human-like language. It’s “large” because it contains billions (or even trillions) of parameters – the internal settings that define how the model responds to text inputs. Training a model involves billions of examples and results in a system with millions or billions of parameters — numerical values the model adjusts during learning to improve its predictions.
In other words, it is a neural network trained to predict the next word (or token) in a sequence. It's not programmed with explicit rules — instead, it learns statistical patterns in large amounts of text data. For example, "I went to the market to buy something fresh..."
The model predicts: "...fruits and vegetables for dinner tonight."
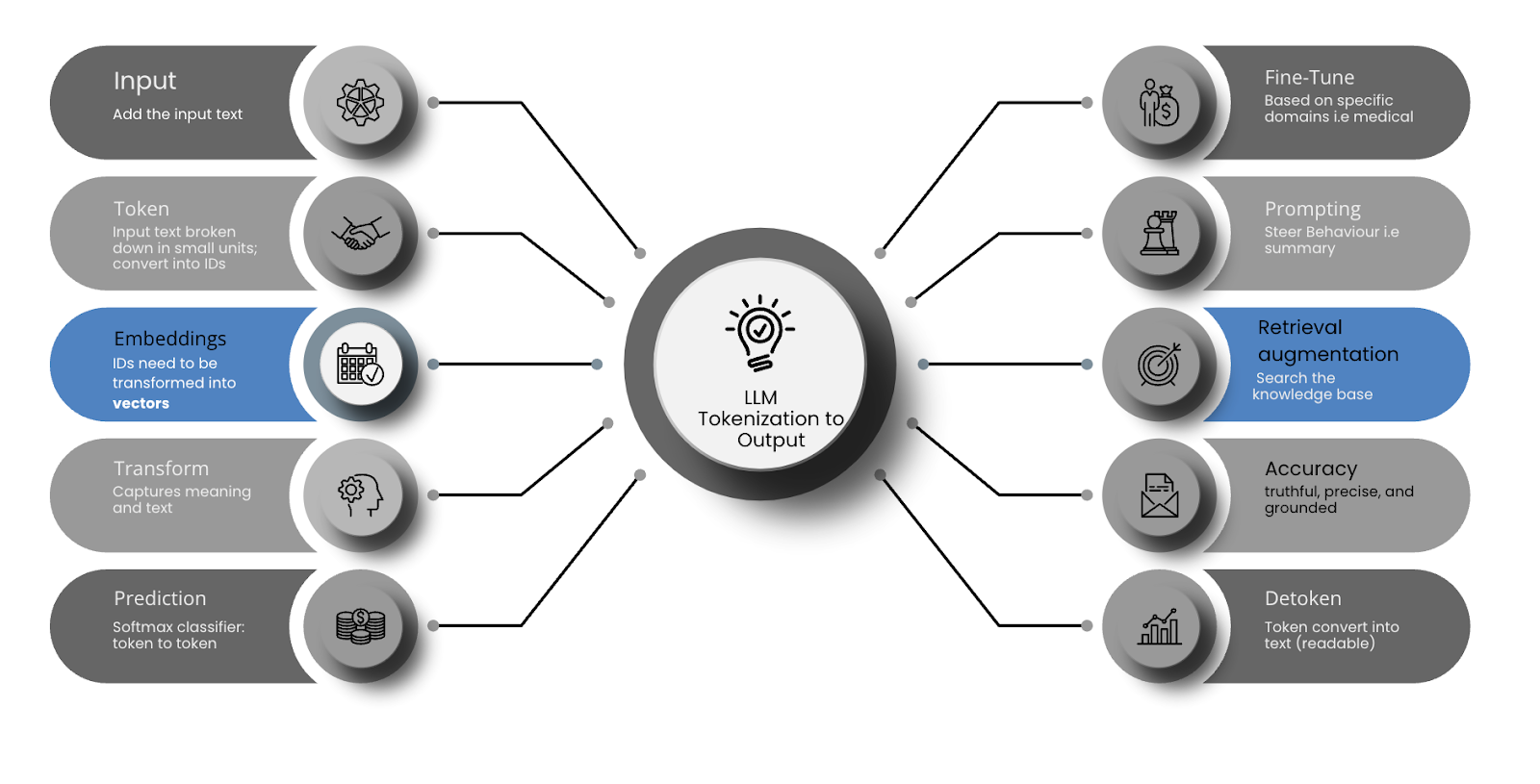
Before any text can be processed, it must be broken down into smaller units. This step is called tokenization.
Computers don't understand words or grammar. They understand numbers. So we convert words into manageable chunks (tokens) and then assign each one a unique ID.
The result: Input text → token sequence → integer IDs
Example: “The dog runs” → [1212, 92, 3190] (IDs depend on the model’s vocabulary)
Once the text is tokenized into IDs, those IDs need to be transformed into vectors — numerical representations that capture relationships between tokens.
These vectors are called token embeddings. For example, the word “king” might be represented as a 768-dimensional vector with floating-point values.
The idea is that similar words (like “king” and “queen”) will have similar vector representations. This allows the model to reason about semantic similarity.
At this point, each token is now a point in a high-dimensional space.
The transformer architecture, introduced by Vaswani et al. in 2017, is the foundation of modern LLMs. It's what allows models to process sequences of text in a way that captures meaning and context.
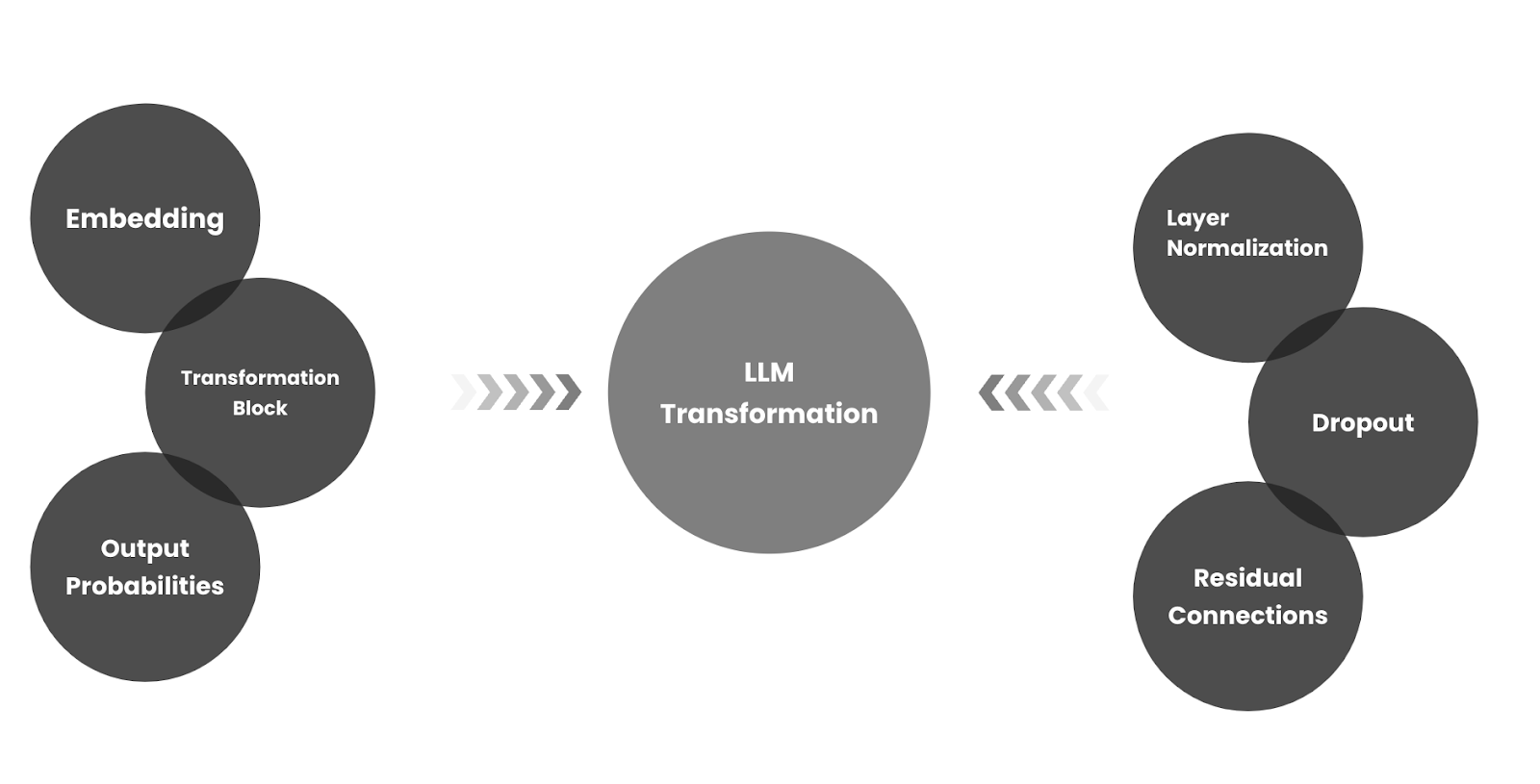
Key components of transformers:
The core innovation is self-attention — the ability of the model to determine which parts of the input are most relevant to a given token.
Example: In the sentence “The dog chased the cat because it was fast,” attention helps resolve that “it” refers to “cat”.
Instead of using one attention calculation, transformers use multiple "heads" to capture different types of relationships between words — syntax, grammar, meaning, etc.
Transformers are composed of many stacked layers. Each layer refines the token vectors based on increasingly abstract patterns.
Once the input has been processed through the transformer stack, the model produces a final vector for each token position. These are fed into a softmax classifier, which outputs a probability distribution over the vocabulary for the next token.
For example:
This process repeats token by token until a stopping condition is reached (such as an end-of-sentence token or length limit).
After the base model is trained (pretraining), it can be:
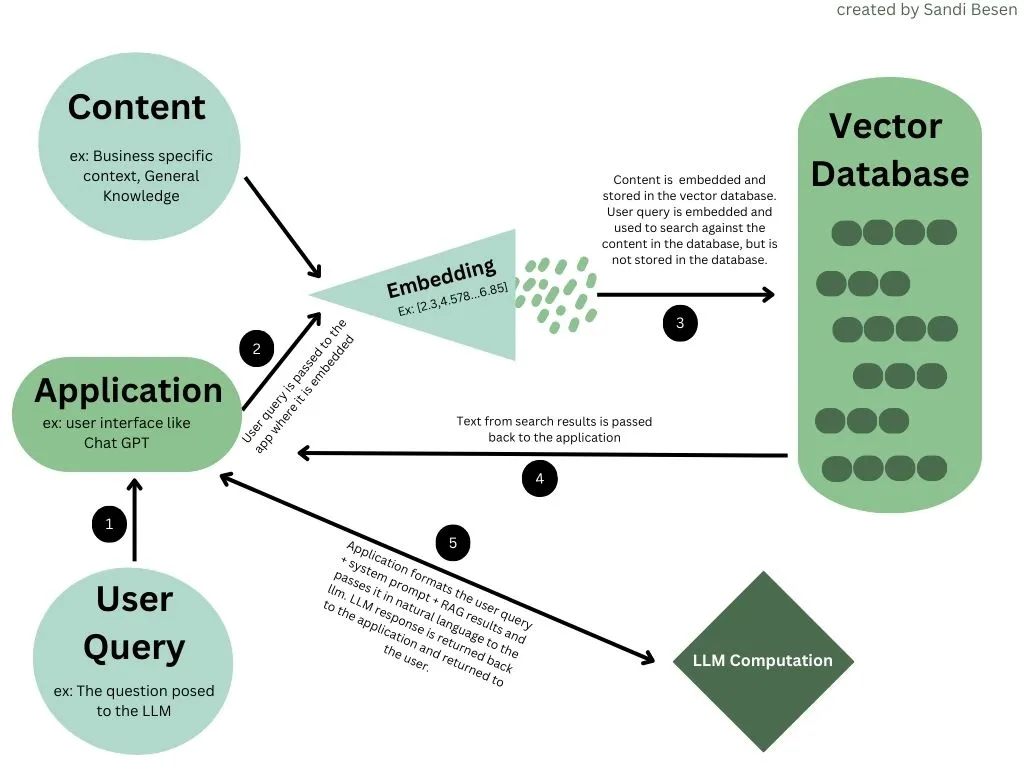
Advanced models can also use retrieval augmentation, tools, or memory to improve factual accuracy and continuity — though these are external to the LLM core.
Common Issues in LLM Outputs:
Because the model is predicting rather than fact-checking, certain problems can arise:
1. Hallucination
What it is: The model generates false or fictional information with high confidence.
Example: “The Eiffel Tower is in Berlin.”
Why it happens: The model aims for fluency, not accuracy. It doesn't have a built-in fact-checking mechanism.
2. Bias
What it is: Outputs reflect biases present in the training data.
Types: Gender, racial, cultural, political.
Example: Associating leadership with male pronouns more often than female.
Why it happens: Models absorb patterns from real-world data, which itself is often biased.
Here’s a simplified flow of how an LLM processes text:
LLMs don’t think, reason, or understand language the way humans do. But by learning statistical patterns in vast amounts of data and representing text as mathematical structures, they can mimic understanding impressively well.
Understanding tokenization, embeddings, and transformers is key to working effectively with LLMs — whether you’re a developer, product manager, or enterprise architect.
If you’re using LLMs in your business, this knowledge can help you interpret their output, design better prompts, and understand where human oversight is essential.
References:
https://poloclub.github.io/#page-top
https://zitniklab.hms.harvard.edu/projects/MedTok/
https://arxiv.org/abs/1706.03762
https://pub.aimind.so/llm-embeddings-explained-simply-f7536d3d0e4b
Level 3, Customs House, 31 Alfred St, Sydney, NSW 2000
Level 3, 162 Collins Street, Melbourne VIC 3000
Office 413-415, 4th Floor, Signature Tower, Lal Kothi Scheme, DC II, Tonk Road, Jaipur - 302015
Tower B, Office No - 1604, 16th Floor, Mont Claire Office Spaces by Mont Vert, Baner-Pashan Link Road, Pune - 411021
Level 3, Customs House, 31 Alfred St, Sydney, NSW 2000
Level 3, 162 Collins Street, Melbourne VIC 3000
Office 413-415, 4th Floor, Signature Tower, Lal Kothi Scheme, DC II, Tonk Road, Jaipur - 302015
Tower B, Office No - 1604, 16th Floor, Mont Claire Office Spaces by Mont Vert, Baner-Pashan Link Road, Pune - 411021
